[C++] 深入了解左值与右值
C:左值与右值
最初,C 语言中的左值(lvalue)意味着任何可以赋值的东西,因为它们可以放在赋值等号的左边,因此它们被命名为左值;相反地,那些只能放在赋值等号右边的东西就被称为右值(rvalue)。
时过境迁,随着 C 语言的版本迭代,这种分类方法已经不再具有价值,左值和右值的定义也随之发生改变。
但是在开始之前,我们需要特别明确一个概念:左值和右值在 C/C++ 中是表达式(expression)的一种属性,被称为值类别(value categories),因此,在部分其他语言中(例如 Rust)会放弃左值和右值的概念,转而使用位置表达式(place expression)和值表达式(value expression)来描述这一属性。
现在,让我们来看看现代 C 语言是如何定义左值的。
《Rationale for International Standard Programming Languages C》说:
A difference of opinion within the C community centered around the meaning of lvalue, one group considering an lvalue to be any kind of object locator, another group holding that an lvalue is meaningful on the left side of an assigning operator. The C89 Committee adopted the definition of lvalue as an object locator. The term modifiable lvalue is used for the second of the above concepts.
C 社区内的意见分歧集中在左值的含义上,一些人认为左值是任何类型的对象定位器,另一些人则认为左值定义为在赋值运算符的左侧时才有意义。C89 委员会采用了对象定位器作为左值的定义。术语“可修改的左值”被用于上述第二个概念。
《ISO/IEC 9899:201x》(即 C11 标准文档)说:
An lvalue is an expression (with an object type other than void) that potentially designates an object.
左值是一个隐含地指定一个(除 void 之外的对象类型的)对象的表达式。
那么新版本的左值和以前的左值(即现在的可修改的左值(modifiable lvalue))有什么区别呢?仍然看到《ISO/IEC 9899:201x》:
A modifiable lvalue is an lvalue that does not have array type, does not have an incomplete type, does not have a const-qualified type, and if it is a structure or union, does not have any member (including, recursively, any member or element of all contained aggregates or unions) with a const-qualified type.
一个可修改的左值是一个没有数组类型、没有不完整类型、没有 const 限定的左值,并且如果它是结构体或者联合体,则没有任何成员(递归地包含任何成员和所有聚合体、联合体的元素)具有 const 限定。
反过来说就是,除了可修改的左值外,还存在数组类型的左值、不完整类型的左值或者具有 const 限定的左值。
数组类型的左值和 const 限定的左值不能被修改我相信是比较常识性的东西:
1
2
3
4
int arr[12] = {0};
// arr = other; --> 编译失败
const int num = 1;
// num = 2; --> 编译失败
不完整的类型做左值的情况,主要还是前置声明:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
struct X;
struct X obj;
void test1() {
// struct X 是不完整的类型,obj 此时不能被修改
// 下面这行代码会报错 error: ‘obj’ has an incomplete type ‘struct X’
// obj = (struct X){};
}
// 定义 struct X
struct X { int i; };
void test2() {
// struct X 现在完整了,obj 此时是可修改的左值
obj = (struct X){ i: 2 };
}
需要注意的是,C11 标准中及其避讳右值的说法,《ISO/IEC 9899:201x》说到:
What is sometimes called “rvalue” is in this International Standard described as the “value of an expression”.
有时被称为“右值”的东西在国际标准中被描述为“表达式的值”。
在 C 语言中,除了左值和右值,还有第三种值类别:函数指代器(function designator),用于描述由于声明函数而引入的标识符的值类别。不过该类别在 C++ 中已经不存在,并且本篇的重点也是 C++ 而不是 C,我们可以无视它。
C++:左值,亡值与纯右值
由于 C++11 引入了全新的移动语义,因此 C++11 也对值类别进行了重新定义。在 C++ 中,表达式的值类别只属于三种基本值类别之一:左值(lvalue),亡值(xvalue)以及纯右值(prvalue)。
注意:在 C++ 中不再区分函数指代器,函数的名字也被归类为左值。
在此之上,C++ 还引申出了两种混合值类别:泛左值(glvalue),包含左值与亡值;右值(rvalue),包含纯右值和亡值。
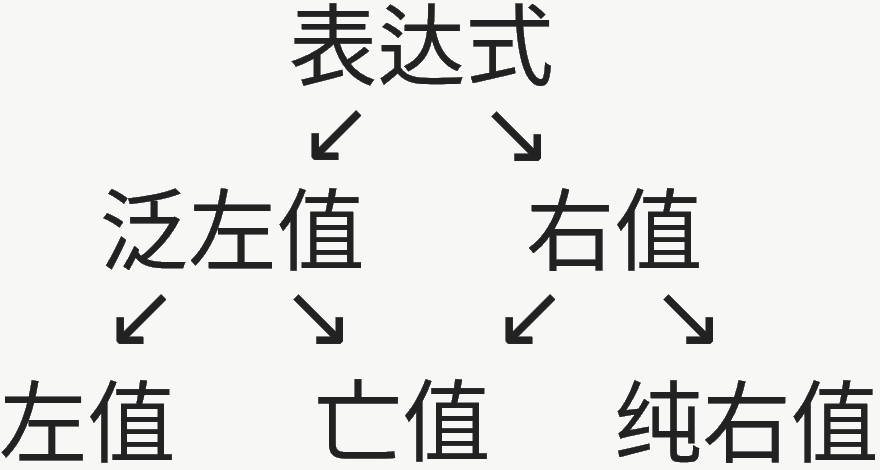
从上面可以看出,在 C 语言的基础上,C++ 特别从右值中将亡值的概念给拆了出来,并且亡值可以和左值共同组合成泛左值。
那么这个亡值究竟是啥呢?我们看看《C++ International Standard 2020 edtion》是怎么定义的:
An xvalue is a glvalue that denotes an object or bit-field whose resources can be reused (usually because it is near the end of its lifetime).
一个亡值是一个表示其资源可以被重用的对象或位字段(通常是因为它已接近其生命周期的末尾)的泛左值。
那么,什么样的值可以算得上是一个亡值呢?《C++ International Standard 2020 edtion》详细介绍了所有情况:
An expression is an xvalue if it is:
- the result of calling a function, whether implicitly or explicitly, whose return type is an rvalue reference to object type,
- a cast to an rvalue reference to object type,
- a subscripting operation with an xvalue array operand,
- a class member access expression designating a non-static data member of non-reference type in which the object expression is an xvalue, or
- a
.*pointer-to-member expression in which the first operand is an xvalue and the second operand is a pointer to data member.In general, the effect of this rule is that named rvalue references are treated as lvalues and unnamed rvalue references to objects are treated as xvalues; rvalue references to functions are treated as lvalues whether named or not.
一个表达式是亡值如果它是:
- 调用函数的结果,且无论是隐式还是显式,其返回类型是对象类型的右值引用,
- 转换到对象类型的右值引用,
- 带有亡值数组操作数的(内建)下标运算,
- 类成员访问表达式,且该成员是非引用类型的非静态数据成员,并且对象表达式是亡值,或者
.*指向成员的指针表达式,其中第一个操作数是亡值,第二个操作数是指向数据成员的指针。通常,此规则的效果是具名右值引用被视为左值,而对对象的不具名右值引用被视为亡值;无论是否具名,对函数的右值引用都被视为左值。
对于上述五种情况,我们分别举例:
-
std::move(a)是亡值 -
static_cast<char &&>(ch)是亡值 -
a[n]当a或n是亡值数组时为亡值(插播一条冷知识:C++ 标准中arr[1]和1[arr]是等效写法)。 -
a.m当a是亡值且m是非引用类型且非静态成员时为亡值(就是类型不是T&或者T&&或者带static的成员)。 -
a.*mp当a是亡值时。
需要注意的是,在 cppreference 中,后三条中的“亡值”被替换为了“右值”(即“亡值”加上“纯右值”),但这并不是谁写错了或者出现了纰漏,根据《C++ International Standard 2020 edtion》描述,纯右值具有以下性质:
Whenever a prvalue appears as an operand of an operator that expects a glvalue for that operand, the temporary materialization conversion is applied to convert the expression to an xvalue.
任何时候,当纯右值作为运算符的操作数出现,且要求该操作数为泛左值时,就会应用临时量实质化转换来将表达式转换为亡值。
临时量实质化转换(temporary materialization conversion)是一个专用术语,专门用于描述任何完整类型 T 的纯右值,可转换成同类型 T 的亡值这一概念。
临时量实质化转换最常见的发生情景是将纯右值绑定到 const 限定的左值引用上:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <iostream>
class Test {
public:
Test(int value) { p = new int(value); }
// 注:其实本例中不涉及拷贝构造函数,因为 C++17 会进行强制的复制消除
Test(const Test &other) { p = new int(*other.p); }
~Test() {
delete p;
p = nullptr;
}
int *p;
};
Test return_prvalue() { return Test(11514); }
int main() {
const Test &ref = return_prvalue();
std::cout << "What will happen if I access ref.p: " << *ref.p << std::endl;
}
如上所示,return_prvalue() 函数返回一个纯右值,而 ref 是一个引用,那么问题来了:这段代码是否会因为 ref 绑定的那个对象被析构从而导致下一行访问 ref.p 时发生未定义行为?
答案是:不会,这里发生了临时量实质化转换,return_prvalue() 返回的纯右值被转换为了亡值。或者,我们加一条 log 能更清晰地了解发生了什么事:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <iostream>
class Test {
public:
Test(int value) { p = new int(value); }
Test(const Test &other) { p = new int(*other.p); }
~Test() {
std::cout << "~Test()" << std::endl;
delete p;
p = nullptr;
}
int *p;
};
Test return_prvalue() { return Test(11514); }
int main() {
const Test &ref = return_prvalue();
std::cout << "What will happen if I access ref.p: " << *ref.p << std::endl;
}
你会发现一个很神奇的事:先打印了 "What will happen if I access ref.p: ",后打印 "~Test()"。这说明返回的纯右值所转换成的亡值,其生命周期被扩大到了整个 main() 函数的函数体。从另一个角度来理解,这里发生的事情类似于使用了一个临时的匿名变量储存了这个纯右值(注意这里的措辞是“类似于”,并不是说一定是这样实现的)。
C:复合字面量
在 C++ 中,绝大部分字面量(如 12, true, nullptr 等)都是纯右值。但是有一个例外,字符串字面量(string literal)是左值。
在谈论为什么字符串字面量是左值之前,我们需要先来了解 C 语言中的一个概念:复合字面量(compound literal)。复合字面量是形如 (T){ ... } 形式的字面量,其中我们最为关心的是当 T 为数组时的形式:(int[]) { 1, 2, 3 },该表达式在 C 语言中是一个左值。
这意味着,下面这串代码,在 C 语言中是完全合法合规已定义的行为:
1
2
3
4
5
6
7
#include <stdio.h>
int main() {
int *p = (int[]){1, 2, 3};
p[1] += 10;
printf("%d\n", p[1]);
}
当然,C 标准并没有规定编译器要怎么实现这一特性,但是我们可以参考一下 GCC 的实现描述:
Here is an example of constructing a struct foo with a compound literal:
This is equivalent to writing the following:
可以看到 GCC 的实现方式是在当前域定义了一个临时的变量作为复合字面量的值,因此它是左值。
C++:字符串字面量
在 C++ 中,不再有复合字面量的概念。在 GCC 的扩展语法中,虽然仍然可以使用复合字面量,但是复合字面量表达式被视为返回一个临时值,该临时值是纯右值且其生命周期不会超过当前语句。由于变量 p 的类型是指针,因此这里还会发生数组到指针的隐式类型转换,然而取址运算的操作数必须是左值,因此 C++(带有 GCC 扩展)将拒绝编译 int *p = (int[]){1, 2, 3};。
顺便一提,即使没有 GCC 扩展,我们也可以在 C++ 中写出纯右值数组。
1
2
3
4
5
6
7
8
9
10
void test_array_prvalue(int (&&a)[4]) {}
// 方案一,基于 typedef 或 using
typedef int arr_t[4]; // 或
using arr_t = int[4];
test_array_prvalue(arr_t{1, 2, 3, 4});
// 方案二,基于 type_identity
#include <type_traits>
test_array_prvalue(std::type_identity_t<int[]>{1, 2, 3, 4});
若想在 GCC 中进行测试,可以添加 -pedantic-errors 作为编译选项,该选项会让 GCC 禁止编译所有非标准的语法。
事实上,字符串字面量可以视为当 T 为 const char [] 类型时复合字面量的一种特例。虽然 C++ 去掉了复合字面量的概念,但是仍然对字符串字面量进行了保留,因此我们仍然可以在 C++ 中用字符串字面量写出一些只有左值能做到的事情:
1
2
3
4
5
6
// 字符串字面量数组隐式转换为指针
const char *pstr = "hello world!";
// 字符串字面量可以取址
auto pstr = &("hello world");
// auto parr = &(arr_t{1, 2, 3, 4}); // 而纯右值数组则无法取址
某种意义上来说,这也属于 C++ 历史包袱的一部分,在很多其他的现代语(例如:Rust)中,字符串字面量是右值。
最后还要提一下,从字符串字面量隐式转换为字符指针这一行为有一个更标准的定义,参考《C++ International Standard 2020 edtion》所述:
Whenever a glvalue appears as an operand of an operator that expects a prvalue for that operand, the lvalue-to-rvalue, array-to-pointer, or function-to-pointer standard conversions are applied to convert the expression to a prvalue.
任何时候,当泛左值作为运算符的操作数出现,且要求该操作数为纯右值时,会应用左值到右值、数组到指针、函数到指针标准转换将表达式转换为纯右值。
C++:右值引用
请回答一个问题:具有右值引用类型的值是左值还是右值?
如果你的回答是:都可以,那么说明你确实是十分认真地在看这篇文章。
在之前介绍亡值的定义时,有这么一句话:
In general, the effect of this rule is that named rvalue references are treated as lvalues and unnamed rvalue references to objects are treated as xvalues; rvalue references to functions are treated as lvalues whether named or not.
通常,此规则的效果是具名右值引用被视为左值,而对对象的不具名右值引用被视为亡值;无论是否具名,对函数的右值引用都被视为左值。
具体来说,定义 T &&t2 = std::move(t1),则 std::move(t1) 是具有右值引用类型的右值(准确地说是亡值),而 t2 是具有右值引用类型的左值。
至于函数的右值引用始终被视为左值,我们可以用简单的例子验证一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#include <iostream>
// 函数类型的左值引用
typedef void (&func_lref_t)(void);
// 函数类型的右值引用
typedef void (&&func_rref_t)(void);
void print() { std::cout << "hello world!" << std::endl; }
// 返回函数类型的右值引用
func_rref_t rref_print() { return print; }
int main() {
// 由于函数类型的右值引用无论如何都是左值,因此可以绑定到左值引用
func_lref_t f = rref_print();
f();
}
原因也很简单,函数全局静态定义,不存在生命周期的概念,函数类型的“亡值”是没有任何意义的。
另一方面,由于具名的右值引用类型是左值,所以会产生一个很有趣同时也很容易迷惑人的现象:
1
2
3
4
5
6
7
int a = 1;
int &&b = std::move(a);
// int &&c = b; <-- 因为 b 是左值,所以没法绑定到右值引用上
int &&c = std::move(b); // <-- 相反还必须给 b 再使用一次 std::move()
// 这种情况还经常出现在派生类的移动构造函数中
Derived::Derived(Derived &&other): Base(std::move(other)) { ... }
既然说到了右值引用,我们再来说点相关的。我们知道 std::move(t) 的实质就是 static_cast<T &&>(t),那么对于一个已经删除了拷贝构造函数,只允许移动构造的类型(例如:std::unique_ptr),我们想要将 std::queue<T> 的 pop() 函数包装成弹出的同时返回值,下面哪种做法是正确的:
1
2
3
4
5
6
7
8
9
10
11
12
#include <queue>
#include <memory>
std::unique_ptr<int> queue_pop(std::queue<std::unique_ptr<int>> &queue) {
// 选项 A:
std::unique_ptr<int> ptr = std::move(queue.front());
// 选项 B:
std::unique_ptr<int> &&ptr = std::move(queue.front());
queue.pop();
return ptr;
}
答案是 A。这是因为 std::move() 仅仅只是一个强制类型转换,它标记 queue.front() 是亡值,但是本身不做任何额外的事情;真正起到移动数据功能的是 std::unique_ptr 的移动构造函数。在选项 A 中,声明了一个新的对象 ptr,并调用 ptr 的移动构造函数,使得 queue.front() 对象的数据被移动到了 ptr 身上;而在选项 B 中,ptr 仅仅只是一个右值引用,它引用了 queue.front() 但是没有移动它,直到 queue.pop() 发生,被引用的对象析构,ptr 成为了一个危险的悬垂引用(dangling reference)。
需要注意,上述悬垂引用的问题主要存在于使用右值引用绑定一个亡值的情况;如果右值引用绑定一个纯右值,那么该纯右值的生命周期会被延长,也就是说下面这段代码反而是正确的:
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <iostream>
#include <string>
std::string get_string() {
return std::string("hello world!");
}
int main() {
// 这是正确的!纯右值的生命周期会延长,str 不是悬垂引用
std::string &&str = get_string();
// 因此可以随意访问 str
std::cout << str << std::endl;
}
C++:引用限定符
由于 C++11 带来的移动语义与右值引用,一个新的问题浮现出了水面:一个对象当自己是右值时,可以表现出不同行为以进行优化。例如:类型内部有一个 std::vector 向量资源,当对象是左值时,成员函数 getVec() 应当返回左值引用,而当对象是右值时,成员函数 getVec() 可以返回右值引用表示自己的向量资源可以被移动。因此,C++11 引入了引用限定符来实现这一功能,使用方式类似于 const 限定符,只需要将 & 或者 && 放置在非静态成员函数的函数签名后即可:
1
2
3
4
5
6
7
8
9
10
11
12
#include <vector>
class MyResources {
public:
// 对象是左值,返回左值引用
std::vector<int> &getResources() & { return m_resource; }
// 对象是右值,资源可以被移动走,返回右值引用
std::vector<int> &&getResources() && { return std::move(m_resource); }
private:
std::vector<int> m_resource;
};
在 C++23 中更进一步的提出了 deducing this 语法,可以显式指定对象的形参类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <vector>
class MyResources {
public:
// 对象是左值,返回左值引用
std::vector<int> &getResources(this MyResources &self) {
return self.m_resource;
}
// 对象是右值,资源可以被移动走
std::vector<int> &&getResources(this MyResources &&self) {
return std::move(self.m_resource);
}
private:
std::vector<int> m_resource;
};
参考
Rationale for International Standard Programming Languages C